ChatTTS一键包长文本语音生成教程
下载
首先,下载一个ChatTTS的一键包。在这里放一个知乎大佬分享的界面:
https://zhuanlan.zhihu.com/p/700962264?utm_psn=1829365246923505664
下载一键包后只需点击运行.exe即可使用。
运行后可以看到一个这样的界面。
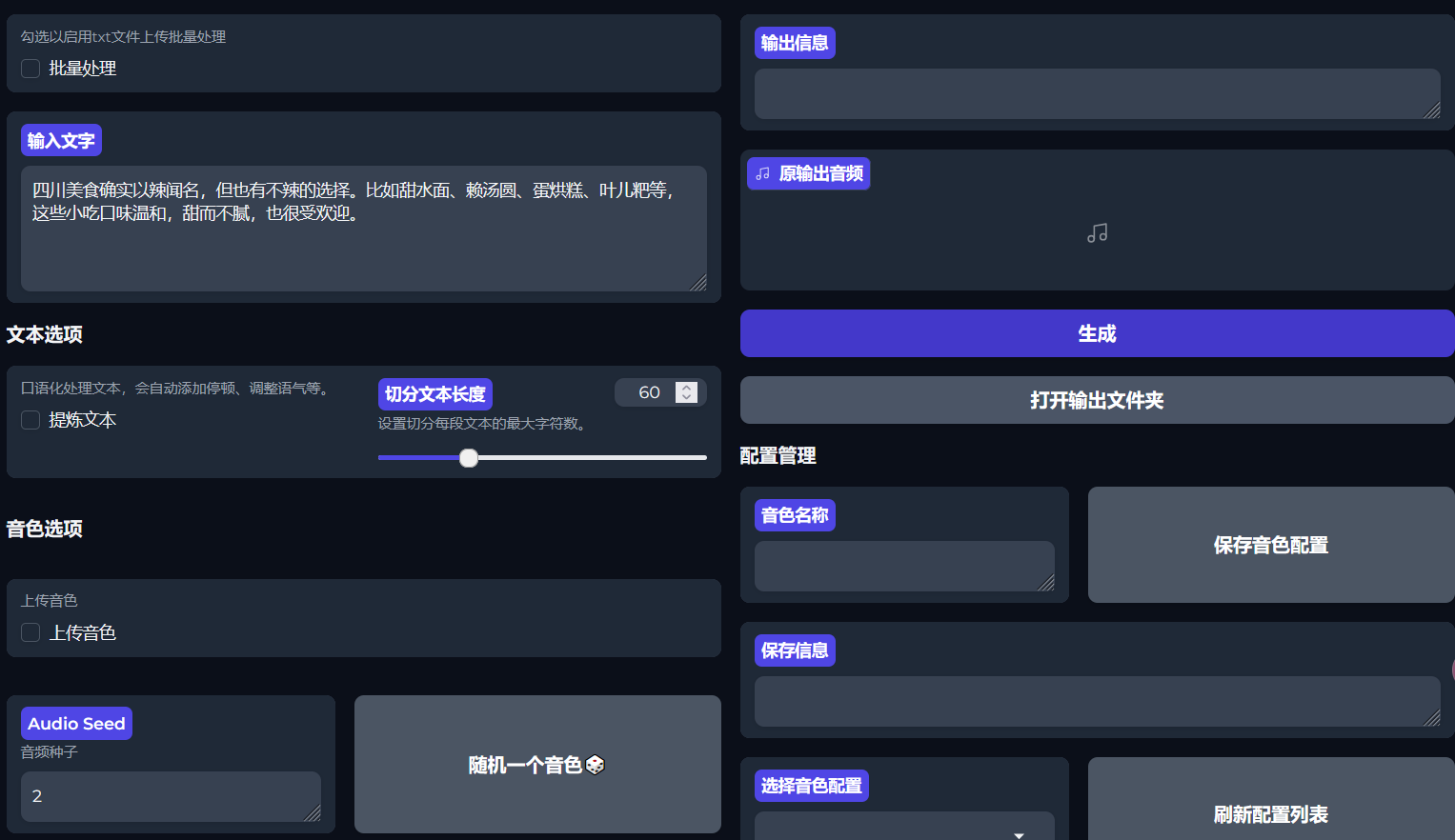
cuda问题
一键包需要匹配的cuda,但我的cuda有问题也能打开并使用一键包,只是不能使用里面的音效增强功能,会报错。
不使用音质增强音效会比较差,我后面用AU解决了这个问题。该教程后面也会附上解决方案。
文本处理
即“勾选以启用txt文件上传批量处理”,就可以上传txt文件或者SRT文件作为要转 语音的文本。
上传前文本预处理
这里主要介绍TXT文件的预处理,SRT文件的没试过。
读长文本的时候需要预处理。特别是想要ChatTTS读一些需要缓慢、温和、稳定的文本,比如说资料、有声书、科普类视频的时候。ChatTTS一键包的语速通常较快(即使把speed这一项拉到0也比较快)所以就需要对文本预处理进行断句。
一键包中经测试停顿代码[uv_break]无法正常使用。会直接被读出来而不是停顿。
建议直接处理文本,逗号就是小停顿。句号是大停顿(但不一定,有的时候ai也会连读)。
一般进行的处理有:
- ChatTTS无法识别冒号、分号、括号、书名号、破折号等等一系列的除了逗号和句号以外的符号。可以在文档里提前把这些符号批量换成逗号或者句号。
在每个句号后面换行。 - 用文心一言这一类文本处理ai按照语言朗读结构在句子停顿处加上逗号。
- 如果句子里逗号太多,就手动把某些逗号改成句号。ai切割会有不合理的地方,记得自己简单看一遍调一下。
- 把文本复制到TXT里导入。
比如说如下长文本:
原子核是原子的核心部分,由质子和中子两种微粒构成。质子又由两个上夸克和一个下夸克组成,而中子则由两个下夸克和一个上夸克组成。
处理后变成了:
原子核,是原子的核心部分。
由,质子和中子,两种微粒构成。
质子,又由两个上夸克,和一个下夸克组成。
而中子,则由两个下夸克,和一个上夸克组成。
提炼文本
勾上。不勾非常捧读。
切分文本长度
自己按需求调。不调也无所谓。
音频选项
音频种子
随机种子比较麻烦,建议在这个网站找种子。
https://modelscope.cn/studios/ttwwwaa/ChatTTS_Speaker/summary
网站里有表格,备注了男声女声,声音年龄段,文本朗读稳定度等信息,点击种子id可在表格下方试听,可下载种子文件。
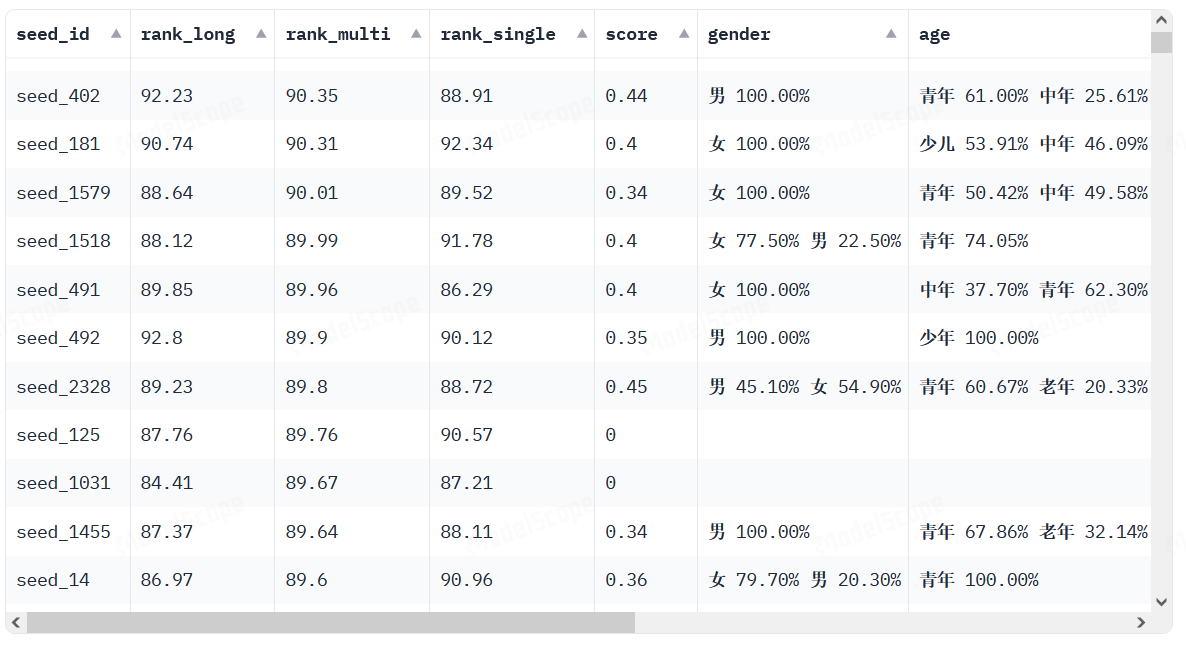
下载种子文件再上传到一键包就好了。网站里的种子编号和一键包不是对应的。
文本种子
比较玄学。就算是一个感情多读几遍,读出来也差异巨大。有心理作用想调可以调一下,不调也无所谓。
语速
一般是0,右拉是变快,不能变慢。
口语化程度
如果读有声书、科普类视频配音之类的就拉到0,不然莫名其妙的语气词会非常多。就算拉到0也有零星几个,需要后期自己手动消掉。
笑声
不需要的时候都是0。
停顿
按需要调整,不要调到大于6,会吞掉停顿后面的一部分语音。
音频增强
都勾上,但可能会报错。
ODE Solver
最高质量RK4
其他参数
不用调
保存种子及音色配置
在配置管理的音色名称中打种子你自定义的配置名称,点保存音色配置就行了。下次要用的时候点选择音色配置并应用配置。
一些可能遇到的问题
1. 因为ChatTTS每句话都是分开生成然后合并在一起的。每句话之间语气、语速、音量大小差异巨大怎么办?
语气问题:一般我会相同的参数重复生成3段音频,导入AU,然后一句话一句话试听,把我觉得最好的段落都剪辑在一起。
语速问题:大部分依靠上面提到的文本预处理和剪辑。少部分用AU自带的音频伸缩,直接拉,10%以内的调节音调差异都比较小。
音量问题:
导入AU,转换成立体声。
在收藏夹里使用AU自带的“标准化为-3dB”。
手动粗略地按段落分区拉一下那些音量特别小的部分,因为有的音量真的太小了,用插件不好调。
用AU的插件或者其他音频处理软件平衡音量。网上有很多教程,可以直接搜索。
2. 手动粗略地按段落分区拉一下那些音量特别小的部分,因为有的音量真的太小了,用插件不好调
- 用AU的滤波器或者其他音频处理软件平衡音量。网上有很多教程,可以直接搜索。
3. 句子里在不该停顿的地方停顿了怎么办?或者没有在该停顿的地方停顿怎么办?
- 要么重新生成这句话,直到生成你想要的,然后剪辑进来。要么用其他音频处理软件剪辑。推荐前一种办法,比较自然。
4. 声音不够好听怎么办?
- AU或者其他调音软件自调。或者多生成几遍这句话找一个比较满意的。即使完全相同参数生成的声音也有可能有透亮的和闷闷的。